The 101 of Apache spark
We will aproach the most important question we need to know when we work with Spark




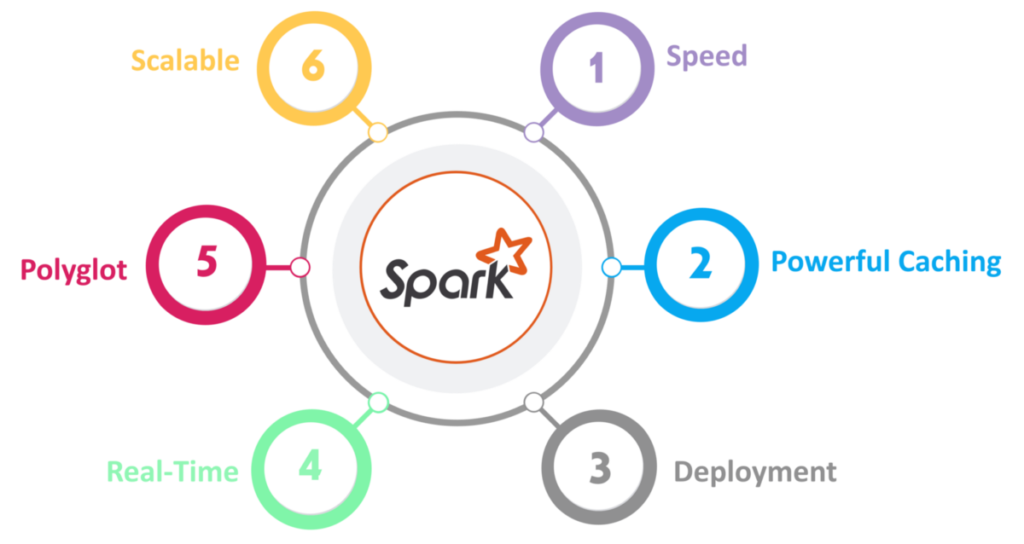
Main features if apache Spark
Performance
The key feature of Apache Spark is its performance. With Apache Spark, we can run programs up to 100 times faster than Hadoop MapRedue in memory. On disk, we can run it 10 times faster than Hadoop.
Integrated Solution.
In Spark, we can create an integrated solution that combines the power of SQL, streaming and data analytics.
Run Everywhere
Apache Spark can run on many platforms. It can run on Hadoop, Mesos, in cloud or standalone. It can also connect to many data sources like HDFS, Casandra, HBase, S3 etc.
Stream Processing
Apache Spark also supports real time stream processing. With real time streaming, we can provide real time analytics solution. This is very useful for real-time data.
Characteristics Resilient distribution dataset in apache spark
Distributed
Data in an R.D.D. is distributed across multiple nodes.
Resilient
R.D.D. is a fault-tolerant dataset. In case of a node failure, Spark can re-compute data.
Dataset
It is a collection of data similar to collections in Scala
Immutable
Data in RDD cannot be modified after creation. But we can transform it using a Transformation.
The most common transformation in Apache Spark
Most frequent transformations
Filter(func)
This transformation returns a new dataset of elements that return true for func functions. It is used to filter elements in a dataset based on criteria in func functions.
Map(func)
A basic transformation that returns a new dataset by passing each element of the input dataset through func functions.
Union(other dataset)
Used to combine a dataset with another dataset to form a union of two datasets.
Intersection(other dataset)
This transformation gives the elements common to two datasets.
Pipe(command,[envVars]
Transformation passes each partition of the dataset through a shell command.
Apache Spark main operations in an RDD
Transformation
This is a function that is used to create a new RDD out of an existing RDD.
Action
This is a function that returns a value to the driver program after running a computation on RDD.
Difference between Transformer and Estimator
Transformer
A transformer is an abstraction for feature transformer and learned model. A Transformer implements transform() methhod. It converts one DataFrame to another DataFrame. It appends ine or more columns to a DataFrame.
Estimator
An estimator is an abstraction for a learning algorithm that fits or trains on data.
A Estimator implements fit() method. The fit() method takes a DataFrame as input and results in a Model.
Apache Spark pass functions
Anonymous function syntax
This is used for passing short pieces of code in an anonymous function.
Static methods in a singleton object
We can also define static methods in an object with only one instance, i.e. singleton. This object along with its methods can be passed to cluster nodes.
SECURITY OPTIONS IN SPARK
Encryption
Apache spark supports encryption by SSL. We can use HTTPS protocol for secure data transfer. Therefore, data is transmitted in encrypted mode. We can use Spark.SSL parameters to set the SSL configuration.
Authentication
R.D.D. is a fault-tolerant dataset. In case of a node failure, Spark can re-compute data.
Event Logging
If we use event logging, then we can set the permissions on the directory where events logs are stored. These permissions can ensure access control for event log.
- Scheduler task and stages
- R.D.D. Size and memory usage.
- Spark Environment information
- Executor information.
Monitoring apache spark
We can use the Web UI provided by SparkContext to monitor Spark. We can access this web UI at port to get the useful information.
Spark also provides a Metric library. This library can be used to sent Spark information to HTTP, JMX, CSV files etc. This is another option to collect Spark runtime information for monitoring another dashboard tool.
Main Libraries in APACHE spark
Mlib
This is Spark's machine learning library. We can use it to create a scalable machine learning system. We can use various machine learning algorithms as well as features like pipe lining etc. with this library.
Spark Sql
This is another popular component that is used for processing SQL queries on Spark platform.
SparkR
This is a package in Spark to use Spark from R language. We can use R data frames, dplyr etc. from this package. We can also start SparkR from RStudio.
Structured Streaming
This library is used from handling streams in Spark. It is a fault tolerant system build on top of Spark SQL Engine to process streams.
GrapX
This library is used from computation of Graphs. It helps in creating graph abstraction of data and then use various graph operators like Sub-Graph, join Vertices etc.
Spark core functions
There are like distribute the task to different nodes
The Scheduling of the jobs on what time, where and if can be done in parallel
This is the part where a spark can read files and write

Read More
Memory tuning in Spark
- Amount of memory used by objects
- Cost of accessing objects
- Overhead of garbage collection
Apache Spark stores objects in memory for caching. So it becomes important to perform memory tuning in Spark application.
First, we determine the memory usage by the application. To do this, we first create an R.D.D. and put it in the cache. Now we can see the size of the R.D.D. on the storage page of Web UI. This will tell the amount of memory consumed by R.D.D.
Base on the memory usage, we can estimate the amount of memory needed for our task. In case we need tuning, we can follow these practices to reduce memory usage.
Use data structures like array of objects or primitives instead of linked list or hashMap. Fastutil library provides convenient collection classes for primitive types compatible with Java.
We can also use JVM flag -XX: +UseCompressedOops to make pointers to be four bytes instead of eight.
Apache Lazy evaluation
Apache Spark uses lazy evaluation as a performance optimization technique.
In lazy evaluation, a transformation is not applied immediately to an RDD.
Spark records the transformation that have to be applied to an RDD.
Once an action is called, spark executes all the transformations.
Ways to create RDD in Spark
Internal
We can parallelize an existing collection of data within our Spark Driver program and create an R.D.D. out of it.
External
We can create an R.D.D. by referencing a dataset in an external data source like AWS S3, HDFS, HBase, local files system, Cassandra etc.
It does not need only a file system for running Spark applications.
Common actions in Apache Spark
Most frequent actions in Spark
Reduce(func)
This action aggregates the elements of a dataset by using func function.
Take(n)
This action gives the first n elements of a dataset.
Collect()
This action will return all the elements of a dataset as an array to the driver program.
First()
This action gives the first elements of a collection.
Foreach(func)
This action runs each element in the dataset through a for loop and executes function func on each element.
Operations
The Shuffle operations in Spark
- Shuffle operation is used in Spark to redistribute data across multiple partitions.
- It is a costly and complex operation.
- In general, a single task in Spark operates on elements in one partition. To execute Shuffle, we have to run an operation on all elements of all partitions. It is also called an all-to-all operation.
Operation that cancause a shuffle in Spark
- Repartition
- Coalesce
- GroupByKey
- ReduceByKey
- Cogroup
- Join
Sparks SQL
What is the purpose of Spark SQL
Spark SQL is used for running SQL queries. We can use Spark SQL to interact with SQL as well as dataset API in Spark.
During execution, Spark SQL uses the same computation engine as SQL, as well as a dataset API.
We can also use Spark SQL to read data from an existing Hive installation
Spark SQL can also be accessed by using JDBC/ODBC API as well as the command line.
What is the data-frame in Spark SQL
In Java and Scala, a DataFrame is represented by a DataSet of rows.
A DataFrame in Spark SQL is a dataset organized into names columns. It is conceptually like a table in SQL.
We can create a Dataframe from:
- An existing RDD.
- A Hive table
- From Other Spark data source.
Parquet file
In Apache Spark.
During write operations, by default, all columns in a parquet file are converted to nullable column.
Apache parquet is a columnar storage format that is available to any project in Hadoop ecosystem.
Any data processing framework, data model or programming language can use it.
It is a compressed, efficient and encoding format common to Hadoop system projects.
Spark SQL support both reading and writing of parquet file. Parquet file schema of the original data.
Apache Spark improvements over Hadoop MaprReduce
Memory
Apache Spark stores data in memory, whereas Hadoop MapReduce stores data in hard disk.
Speed
Apache Spark is from 10 to 100 times faster than Hadoop MapReduce due to its usage of in-memory processing.
RDD
Spark uses resilient distributed dataset (RDD) that guarantee fault tolerance. Where Apache, Hadoop uses replication of data in multiple copies to achieve fault tolerance.
Streaming
Apache Spark supports streaming with very less administration. This makes it much easier to use than Hadoop for real-time stream processing.
API
Spark provides a versatile API that can be used with multiple data sources as well as languages. It is more extensible than the API provided by Apache Hadoop.
Operations
Spark file systems suported
- HDFS
- S3
- Local file system
- Cassandra
- OpenStack Swift
- MapR Files Systems
Main languages supported by Apache Spark
Java
We can use Java Spark Context object to work with Java in Spark.
Scala
To use Scala with Spark, we have to create Spark Context object in Scala
R
We can use SparkR module to work with R language in Spark ecosystem.
Python
We also use Spark Context to work with Python in Spark
Sql
Working with Spark SQL to use the SQL language in spark.
Apache Spark lineage
RDD.
Resilient distributed dataset lineage is a graph of all the parent RDD of an RDD. Since spark does not replicate data, it is possible to lose some data.
In the dataset.
In case some dataset it's lost, it is possible to use RDD lineage to recreate the lost dataset.
Lineage as a solution.
Therfore RDD lineage provides solution for better performance of Spark as well as it helps in building a resilient system.
Spark vectors main types.
Dense Vector
A dense vector is backed by an array of double data type. This array contains the values.
E.g. {1.0, 0.0, 3.0}
Sparse Vector
A sparse vector is backed by two parallel arrays. One array is for indices and the other array values.
E.g. {3, [0,2],[1.0,3.0]}
Deployments modes of Apache Spark
Standalone
This is the mode in which we can start Spark by hand. We can launch standalone clusters manually.
Mesos
We can deploy a spark application in a private cluster by using Apache Mesos.
yarn
We can also deploy on Apache YARN (Hadoop Next Gen).
Amazon ec2
We can use AWS cloud product Elastic Compute Cloud (AWS EC2) to deploy and run a Spark cluster.
Cluster manager in apache spark
StandAlone
It is a simple cluster manager that is included with Spark. We can start Spark manually by hand in this mode.
Spark on Mesos
In this mode, Mesos master replaces Spark master as the cluster manager. When driver creates a job, Mesos will determine which machine will handle the task.
Hadoop YARN
In this setup, Hadoop YARN is used in cluster. There are two modes in this setup. In cluster mode, spark driver runs inside a master process manager by YARN on cluster. In client mode, the Spark Driver runs in the client process and application master is used for requesting resources from YARN.
Differences between Cache() and persist() methods in Apache Spark
Both cache() and persist() functions are used for persisting a RDD in memory across operations.
Storage Level
The key difference between persist() and cache() is that in persist() we can specify the storage level that we select for persisting.
Memory only
Where as in cache(), default strategy is used for persisting. The default storage strategy is MEMORY_ONLY.
Core components of Apache Spark
Executor
This is a process on a worker node. It is launched on the node to run an application. It can run tasks and use data in memory or disk storage to perform the task.
This is the component responsible for launching executors and drivers on multiple nodes. We can use different types of cluster managers based on our requirements. Some common types are Stand-Alone YARN and Mesos.
Driver
This is the main program in the spark that runs the main() function of an application. A driver program creates the spark context. Driver program listens and accepts incoming connections from its executors.
Remove data from cache in Apache Spark
Automatic
There are automatic monitoring mechanisms in Spark to monitor cache usage on each node.
RDD un persist
In case we want to forcibly remove an object from the cache in Apache Spark, we can use RDD.unpersist() method.
Least recently used.
In general, Apache Spark automatically removes the unused objects from the cache. It uses Least recently used (LRU) algorithm to drop old partitions.
Spark Context in Apache Spark
Central Object
SparkContext is the central object in Spark that coordinates different Spark applications in a cluster.
In a cluster, we can use SparkContext to connect multiple Cluster Managers that allocate resources to multiple applications.
First
For any Spark program we first create SparkContext Object.
We can access a cluster by using this object.
Spark Config
In order to create a SparkContext object, we first need to create a SparkConf object. This object contains the configuration information of the Spark application.
In Spark shell, by default we get a sparkContext for the shell.
Spark Streaming
Spark Streaming is a very popular feature of Spark for processing live streams with a large amount of data.
Spark Streaming uses Spark API to create a highly scalable, high throughput, and fault-tolerant system to handle live data streams.
Spark Streaming supports ingestion of data from popular sources like Kafka, Kinesis, Flume, etc.
We can apply popular functions like map, reduce, join etc on data processed through spark streams
Spark streaming
Streaming in Spark Engine
Spark streams listen to live data streams from various sources. On receiving data, it is divided into small batches that can be handled by the Spark engine.
These small batches of data are processed by Spark Engine to generate another output stream of resultant data.
Spark Stream internal
Internally, Spark uses an abstraction called DStream or discretized stream. A Dstream is a continuous stream of data.
We can create Dstream from Kafka, flume, Kinesis etc.
Structures Streaming in Spark
Structured Streaming is a new feature in Spark 2.1. It is a scalable and fault-tolerant streaming-processing engine. It is built on a Spark SQL engine. We can use dataset or DataFrame API to express streaming aggregations, event-time windows, etc. The computations are done on the optimized Spark SQL engine.
Spark Dstream
A Dstream is nothing but a sequence of RDDs in Spark.
We can apply transformations and actions on this sequence of RDDs to create further RDDs.
Pipeline in Apache Spark
From Machine learnin
Pipeline is a concept from Machine learning It is a sequence of algorithms that are executed fro processing and learning from data. A pipeline is similar to a workflow. Ther can be one or more stages in a pipeline.
Purpose of pipeline
A pipeline is a sequence if stages. Each stage in pipeline can be a transformer or an estimator. We run these stages in an order. Initially a dataFrame is passed as an imput to pipeline. This dataframe keeps on transforming with each stage of pipeline. Most if the time, runtime checking is done on dataframe passing through the pipeline. We can also save a pipeline to a disk. It can be re-read from disk a later point of time.
Minimize data transfer in APACHE spark
Spark.shuffle.compress
This configuration can be set to true to compress map output files. This recuces the amount if data transfer due to compression.
ByKey operations
We can minimize the use of ByKey operations to minimize the shuffle calls.
Uses of MLIB in Apache Spark
Mlib Algorithms
It contains Machine learning algorithms such as classification, regression, clustering, and collaborative filtering.
Featurization
MLIB provides algorithms to work with features. Some of these are feature extractions, transformation, dimensionality reduction, and selection.
Pipelines
It contains tools for constructing, evaluating, and tuning ML Pipelines.
Utilities
It contains utilities for linear algebra, statistics, data handling, etc.
Persistence
Ir also provides methods for saving and load algorithms, models, and pipelines.
Checkpoint Apache Spark
Metadata Check pointing
Metadata is the configuration information and other information that defines s streaming application. We can create a Metadata checkpoint for a node to recover from the failure while running the driver application. Metadata includes configuration, DStream operations and incomplete batches etc.
DAta Checkpointing
In this checkpoint, we save RDD to a reliable storage. This is useful in stateful transformations where generated RDD depends on RDD of the previous batch. There can be a long chain of RDD in some cases. To avoids such large recovery time, it is easier to create Data checkpoint with RDD at intermediate step
Accumulator in Apache Spark
An accumulator is a variable in Spark that can be added only through an associative and commutative operation. Can be supported in parallel.
It is generally used to implement a counter or cumulative sum. We can create numeric type Accumulators by default in Spark. An accumulator variable can be named as well as unnamed.
Neighborhood Aggregation in Spark
Use of aggregation spark
We can aggregateMessages[] and mergeMsg[] operations in Spark for implementing Neighborhood aggregation.
Neighborhood Aggregation in Graphs
Neighborhood aggregation is a concept in the graph module of spark. If refers to the task of aggregating information about the neighborhood of each vertex.
Example of Neighborhood aggregation
We want to know the number of books referenced in a book. Or number of times a tweet is retweeted.
Neighborhood aggregation concept
This concept is used in iterative graph algorithms. Some of the popular uses of this concept are un page rank, shortest path, etc.
Graph Property.
A property graph is a directed multigraph. We can attach an object to each vertex and edge of a Property Graph. In a directed multigraph, we can have multiple parallel edges that share the same source and destination vertex.
During modeling of the data, the option of parallel edges helps in creating multiple relationships between the same pair of vertices.
An example can be, two persons can have two relationships in boss as well as the mentor.
Options to create a Graph
Graph.fromEdgeTuples
WE can also create a graph from only an RDD of tuples.
Graph.apply
This is the simplest option to create a graph. We use this option to create a graph from RDD of vertices and edges.
Graph.fromEdges
We can also create a graph from RDD of edges. In this option, vertices are created automatically, and a default value is assigned to each vertex.
Operations
Graph of basic operators in Spark
- numEdges
- NumVertices
- inDegrees
- outDegrees
- degrees
- vertices
- edge
- persist
- cache
- unpersistVertices
- partitionBy
The approach of partitioning used in GraphX of Apache Spark
Graph X uses the Vertex-cut approach to distributed graph partitioning.
In this approach, a graph is not split along the edge. Rather, we partition graphs along vertices. These vertices can span multiple machines.
This approach reduces communication and storage overheads.
Edges are assigned to different partitions based on the partition strategy that we select.
Persistence level in Apache Spark
MEMORY_AND_DISK
In this level, RDD object is stored as a deserialized java object in JVM. If an RDD doesn't fit in memory, it will be stored on the disk.
MEMORY_AND_DISK_SER
In this level, RDD object is stored as a serilized java object in JVM. If an RDD doesn't fir in the memory, it will be stored on the disk.
MEMORY_OLY_SER
In this leve, RDD object is stored as serialized java object in JVM. It is more efficient thatn the serialized object.
MEMORY_ONLY
In this level, RDD object is stored as a deserilized java object in JVM. If an RDD foesn't fit tin the memory, it will be recomputed.
DISK_ONLY
In this level, RDD object is stored only on disk.
Best Storage level in Apache Spark
CPU and Memory balance in Spark
We use storage level to maintain a balance between CPU efficiency and Memory Usage.
If our RDD objects fit in memory, we use the MEMORY_ONLY option. In this option, the performance is very good due to objects being in memory only.
Spark with serialization
In case our RDD objects cannot fit in memory, we go for the MEMORY_ONLY_SER option and select a serialization library that can provide space-saving with serialization.
This option is also quite fast in performance.
Spark in memory and disk
In case our RDD object cannot fit in memory with a big gap in memory vs. total object size, we go for MEMORY_AND_DISK option.
In this option some RDD objects are stored on Disk.
Spark and fast recovery
For fast fault recovery we use replication of objects multiple partitions.
Broadcast Variable in Apache Spark
Purpose of the broadcast variable
The broadcast variable allows a programmer to keep read-only variables cached on each machine rather than shipping a copy of it with the task.
The broadcast variable allows a programmer to keep read-only variables cached on each machine rather than shipping a copy of it with the task.
Use of Broadcast
We can use SparkContext.broadcast(v) to create a broadcast variable. It is recommended that we should use a broadcast variable in place of the original variable for running a function on a cluster.
Broadcast on Shuffle operations
I shuffle operations, there is a need for common data. This common data is broadcast by Spark as a broadcast variable. The data in these variables are serialized and deserialized before running a task.